Weather and Crime Analysis in Louisville, KY
 |
|---|
| Photo credit: alexeys/iStock.com |
Data
For this project, I used 3 datasets that were obtained through three different methods:
- CSV file: Crime in Louisville Dataset 2003-2017
- Website: Zip-codes.com
- API: OpenWeatherMap.org
Objective
The idea is since I want to travel to Louisville, KY for a vacation during the summer. I wanted to see how crime rate in this city has changed over time. In addition, which Zip Code has the most crime counts; since Zip Code is the common variable because for the next two datasets I will use Zip Code to get weather information through OpenWeatherMap and to see the total demographics of that particular Zip Code. I will use this website data file and scrape Zip Codes for Kentucky and use those Zip Codes to pull weather data from the next source of data through the use of API key. Overall, the goal of the project is that I can get weather information for every zip code available in the city of Louisville, KY and also see how the crime rate through different types of crimes are.
Accomplishments
This project gives me an opportunity to understand how to web scrape data from a website using BeautifulSoup, though Scrapy can also be used here. Aside from web scraping, I had to be able to request and get data through an API key and combined all of these data from different sources(csv, website and API) to create a master dataframe and analyze from there.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import norm
df_crime = pd.read_csv('louisville_crime2003to2017.csv')
1) Replace headers
df_crime.head()
| Unnamed: 0 | INCIDENT_NUMBER | DATE_REPORTED | DATE_OCCURED | UOR_DESC | CRIME_TYPE | NIBRS_CODE | UCR_HIERARCHY | ATT_COMP | LMPD_DIVISION | LMPD_BEAT | PREMISE_TYPE | BLOCK_ADDRESS | CITY | ZIP_CODE | ID | Time To Report in Days | YEAR_OCCURED | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 80-13-099806 | 2014-01-01 04:00:54 | 2013-12-20 12:31:00 | FRAUDULENT USE OF CREDIT CARDS U/$10,000 | FRAUD | 26B | PART II | COMPLETED | METRO LOUISVILLE | METRO | OTHER / UNKNOWN | COMMUNITY AT LARGE | LOUISVILLE | 40056 | 830668 | 0.645764 | 2013.0 |
| 1 | 1 | 80-13-099861 | 2014-01-01 09:14:59 | 2013-12-22 03:00:00 | THEFT OR DISP PARTS/CONT FROM VEH UNDER $500 | VEHICLE BREAK-IN/THEFT | 23F | PART I | COMPLETED | 8TH DIVISION | 823 | RESIDENCE / HOME | 14300 BLOCK WAKEFIELD PL ... | LOUISVILLE | 40245 | 830675 | 0.260405 | 2013.0 |
| 2 | 2 | 80-13-099923 | 2014-01-01 19:52:19 | 2014-01-01 18:56:19 | CRIMINAL MISCHIEF-2ND DEGREE | VANDALISM | 290 | PART II | COMPLETED | 6TH DIVISION | 624 | PARKING LOT / GARAGE | 4600 BLOCK WATTBOURNE LN ... | LOUISVILLE | 40299 | 830683 | 0.038889 | 2014.0 |
| 3 | 3 | 80-13-099961 | 2014-01-01 01:38:01 | 2014-01-01 01:19:01 | CRIMINAL MISCHIEF-3RD DEGREE | VANDALISM | 290 | PART II | COMPLETED | 2ND DIVISION | 223 | HIGHWAY / ROAD / ALLEY | S 26TH ST / OSAGE AVE ... | LOUISVILLE | 40210 | 830689 | 0.013194 | 2014.0 |
| 4 | 4 | 80-13-099953 | 2014-01-01 00:05:00 | 2014-01-01 00:00:00 | TERRORISTIC THREATENING 3RD DEGREE | ASSAULT | 13C | PART II | COMPLETED | 4TH DIVISION | 435 | RESIDENCE / HOME | 4000 BLOCK WOODRUFF AVE ... | LOUISVILLE | 40215 | 830798 | 0.003472 | 2014.0 |
# Let's drop a few unwanted columns and only keep those relevant to the project
df = df_crime[['CRIME_TYPE', 'CITY', 'ZIP_CODE', 'YEAR_OCCURED', 'ID']]
df.head()
| CRIME_TYPE | CITY | ZIP_CODE | YEAR_OCCURED | ID | |
|---|---|---|---|---|---|
| 0 | FRAUD | LOUISVILLE | 40056 | 2013.0 | 830668 |
| 1 | VEHICLE BREAK-IN/THEFT | LOUISVILLE | 40245 | 2013.0 | 830675 |
| 2 | VANDALISM | LOUISVILLE | 40299 | 2014.0 | 830683 |
| 3 | VANDALISM | LOUISVILLE | 40210 | 2014.0 | 830689 |
| 4 | ASSAULT | LOUISVILLE | 40215 | 2014.0 | 830798 |
# Let's replace some headers to make it look nicer
df.rename(columns={'CRIME_TYPE': 'crime', 'CITY': 'City', 'ZIP_CODE': 'Zip Code', 'YEAR_OCCURED': 'year'}, inplace = True)
2) Format Data to a Readable Format
# Rearranging the order of some columns
df = df[['ID', 'year', 'crime','Zip Code', 'City']]
df.head()
| ID | year | crime | Zip Code | City | |
|---|---|---|---|---|---|
| 0 | 830668 | 2013.0 | FRAUD | 40056 | LOUISVILLE |
| 1 | 830675 | 2013.0 | VEHICLE BREAK-IN/THEFT | 40245 | LOUISVILLE |
| 2 | 830683 | 2014.0 | VANDALISM | 40299 | LOUISVILLE |
| 3 | 830689 | 2014.0 | VANDALISM | 40210 | LOUISVILLE |
| 4 | 830798 | 2014.0 | ASSAULT | 40215 | LOUISVILLE |
# This will convert zip_code column to string format
df['Zip Code'] = df['Zip Code'].astype(str)
3) Finding Duplicates
# Let's find duplicates and drop these from our dataset
df.drop_duplicates()
| ID | year | crime | Zip Code | City | |
|---|---|---|---|---|---|
| 0 | 830668 | 2013.0 | FRAUD | 40056 | LOUISVILLE |
| 1 | 830675 | 2013.0 | VEHICLE BREAK-IN/THEFT | 40245 | LOUISVILLE |
| 2 | 830683 | 2014.0 | VANDALISM | 40299 | LOUISVILLE |
| 3 | 830689 | 2014.0 | VANDALISM | 40210 | LOUISVILLE |
| 4 | 830798 | 2014.0 | ASSAULT | 40215 | LOUISVILLE |
| ... | ... | ... | ... | ... | ... |
| 1156493 | 1145530 | 2005.0 | DRUGS/ALCOHOL VIOLATIONS | 40219.0 | LOUISVILLE |
| 1156494 | 256019 | 2005.0 | ASSAULT | 40214.0 | LOUISVILLE |
| 1156495 | 257429 | 2005.0 | SEX CRIMES | 40218.0 | LOUISVILLE |
| 1156496 | 260318 | 2005.0 | SEX CRIMES | 40211.0 | LOUISVILLE |
| 1156497 | 636228 | 2005.0 | OTHER | 40203.0 | LOUISVILLE |
1156498 rows × 5 columns
4) Identify Outliers and Bad Data
For outliers, I will focus on year column
df['year'].hist(bins=100)
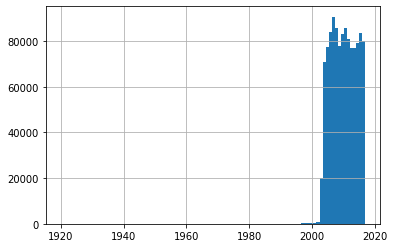
For the year column, anything before Year 2004 are outliers. Thus, I will remove all data for any year before 2004.
df_1 = df[df.year >= 2004]
df_1
| ID | year | crime | Zip Code | City | |
|---|---|---|---|---|---|
| 0 | 830668 | 2013.0 | FRAUD | 40056 | LOUISVILLE |
| 1 | 830675 | 2013.0 | VEHICLE BREAK-IN/THEFT | 40245 | LOUISVILLE |
| 2 | 830683 | 2014.0 | VANDALISM | 40299 | LOUISVILLE |
| 3 | 830689 | 2014.0 | VANDALISM | 40210 | LOUISVILLE |
| 4 | 830798 | 2014.0 | ASSAULT | 40215 | LOUISVILLE |
| ... | ... | ... | ... | ... | ... |
| 1156493 | 1145530 | 2005.0 | DRUGS/ALCOHOL VIOLATIONS | 40219.0 | LOUISVILLE |
| 1156494 | 256019 | 2005.0 | ASSAULT | 40214.0 | LOUISVILLE |
| 1156495 | 257429 | 2005.0 | SEX CRIMES | 40218.0 | LOUISVILLE |
| 1156496 | 260318 | 2005.0 | SEX CRIMES | 40211.0 | LOUISVILLE |
| 1156497 | 636228 | 2005.0 | OTHER | 40203.0 | LOUISVILLE |
1133027 rows × 5 columns
df_1['year'].hist(bins=100)
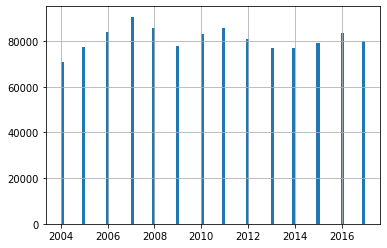
This histogram showing data for all year from 2004 - 2017 is much better now, with no outliers
# Missing or bad data heatmap
cols = df_1.columns[:30]
colours = ['#000099', '#ffff00'] # specify the colours - yellow is missing. blue is not missing.
sns.heatmap(df_1[cols].isnull(), cmap=sns.color_palette(colours))
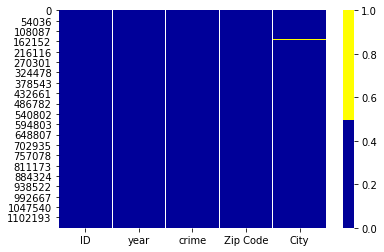
This bad or null data heatmap shows us where the missing data are. Yellow is missing and blue is not. It seems we do not have any missing or null data in our dataset or the missing values population is very small to be observed. Thus, to be sure, I will use dropna() function to drop any NA values.
df_1 = df_1.dropna()
df_1
| ID | year | crime | Zip Code | City | |
|---|---|---|---|---|---|
| 0 | 830668 | 2013.0 | FRAUD | 40056 | LOUISVILLE |
| 1 | 830675 | 2013.0 | VEHICLE BREAK-IN/THEFT | 40245 | LOUISVILLE |
| 2 | 830683 | 2014.0 | VANDALISM | 40299 | LOUISVILLE |
| 3 | 830689 | 2014.0 | VANDALISM | 40210 | LOUISVILLE |
| 4 | 830798 | 2014.0 | ASSAULT | 40215 | LOUISVILLE |
| ... | ... | ... | ... | ... | ... |
| 1156493 | 1145530 | 2005.0 | DRUGS/ALCOHOL VIOLATIONS | 40219.0 | LOUISVILLE |
| 1156494 | 256019 | 2005.0 | ASSAULT | 40214.0 | LOUISVILLE |
| 1156495 | 257429 | 2005.0 | SEX CRIMES | 40218.0 | LOUISVILLE |
| 1156496 | 260318 | 2005.0 | SEX CRIMES | 40211.0 | LOUISVILLE |
| 1156497 | 636228 | 2005.0 | OTHER | 40203.0 | LOUISVILLE |
1128738 rows × 5 columns
We have dropped a total of 7,546 rows containing NA or missing values
5) Fix casing or inconsistent values
I will focus on crime and city column, to fix all capitalization and casing to lowercase for consistency
# Crime column casing fix
df_1['crime'].value_counts()
# make everything lower case.
df_1['crime'] = df_1['crime'].str.lower()
df_1['crime'].value_counts()
theft/larceny 197225
drugs/alcohol violations 191468
other 163155
assault 147072
burglary 99267
vandalism 93438
vehicle break-in/theft 86057
fraud 47101
motor vehicle theft 43314
robbery 22915
disturbing the peace 14381
weapons 12118
sex crimes 8529
dui 1527
homicide 1020
arson 151
Name: crime, dtype: int64
# City column casing fix
df_1['City'].value_counts()
# make everything lower case.
df_1['City'] = df_1['City'].str.lower()
df_1['City'].value_counts()
louisville 1059970
lvil 37551
lyndon 3948
middletown 3901
shively 3829
...
san francisco 1
louisviille 1
fort wayne i 1
louisv 1
houston 1
Name: City, Length: 200, dtype: int64
df_1 = df_1[df_1['City'] == 'louisville']
df_1
| ID | year | crime | Zip Code | City | |
|---|---|---|---|---|---|
| 0 | 830668 | 2013.0 | fraud | 40056 | louisville |
| 1 | 830675 | 2013.0 | vehicle break-in/theft | 40245 | louisville |
| 2 | 830683 | 2014.0 | vandalism | 40299 | louisville |
| 3 | 830689 | 2014.0 | vandalism | 40210 | louisville |
| 4 | 830798 | 2014.0 | assault | 40215 | louisville |
| ... | ... | ... | ... | ... | ... |
| 1156493 | 1145530 | 2005.0 | drugs/alcohol violations | 40219.0 | louisville |
| 1156494 | 256019 | 2005.0 | assault | 40214.0 | louisville |
| 1156495 | 257429 | 2005.0 | sex crimes | 40218.0 | louisville |
| 1156496 | 260318 | 2005.0 | sex crimes | 40211.0 | louisville |
| 1156497 | 636228 | 2005.0 | other | 40203.0 | louisville |
1059970 rows × 5 columns
One last look at our new and finished clean dataframe
df_crime_clean = df_1
df_crime_clean
| ID | year | crime | Zip Code | City | |
|---|---|---|---|---|---|
| 0 | 830668 | 2013.0 | fraud | 40056 | louisville |
| 1 | 830675 | 2013.0 | vehicle break-in/theft | 40245 | louisville |
| 2 | 830683 | 2014.0 | vandalism | 40299 | louisville |
| 3 | 830689 | 2014.0 | vandalism | 40210 | louisville |
| 4 | 830798 | 2014.0 | assault | 40215 | louisville |
| ... | ... | ... | ... | ... | ... |
| 1156493 | 1145530 | 2005.0 | drugs/alcohol violations | 40219.0 | louisville |
| 1156494 | 256019 | 2005.0 | assault | 40214.0 | louisville |
| 1156495 | 257429 | 2005.0 | sex crimes | 40218.0 | louisville |
| 1156496 | 260318 | 2005.0 | sex crimes | 40211.0 | louisville |
| 1156497 | 636228 | 2005.0 | other | 40203.0 | louisville |
1059970 rows × 5 columns
Previously, Milestone 3 goal was to scrape all available Zip codes from Kentucky and put all of the Zip codes into a dataframe. This week’s milestone 4 will use that dataframe to pull weather information using API on OpenWeatherMap
Milestone 3 (Web scraping data source)
The goal of this dataset and milestone is to scrape all available Zip codes from Kentucky for next milestone project to pull weather data from each zip code using API. I will put all Louisville city Zip codes into a data format.
from bs4 import BeautifulSoup
import requests
import json
import pandas as pd
# use get method to send a GET request to the URL
page = requests.post('https://www.zip-codes.com/state/ky.asp')
#passes the HTML of the page into the BeautifulSoup class
bs = BeautifulSoup(page.content)
#Uses Beautiful Soup to find and return all tables with id containing the string "tblZIP"
_tables = bs.find_all("table", id ="tblZIP")
Format data into a more readable format
_zipcodeList = []
# find all a's in the first table
_AList = _tables[0].find_all('a')
# extract 'title' for all a's
for _a in _AList:
if 'title' in _a.attrs.keys():
_title = _a['title']
# extract zipcodes string and append zipcodelist
if _title.startswith('ZIP'):
_zipcodeList.append(_title.split(' ')[-1])
# find length of the zipcodelist and print
print(len(_zipcodeList))
print(_zipcodeList)
944
['40003', '40004', '40006', '40007', '40008', '40009', '40010', '40011', '40012', '40013', '40014', '40018', '40019', '40020', '40022', '40023', '40025', '40026', '40027', '40031', '40032', '40033', '40036', '40037', '40040', '40041', '40045', '40046', '40047', '40048', '40049', '40050', '40051', '40052', '40055', '40056', '40057', '40058', '40059', '40060', '40061', '40062', '40063', '40065', '40066', '40067', '40068', '40069', '40070', '40071', '40075', '40076', '40077', '40078', '40104', '40107', '40108', '40109', '40110', '40111', '40115', '40117', '40118', '40119', '40121', '40122', '40129', '40140', '40142', '40143', '40144', '40145', '40146', '40150', '40152', '40153', '40155', '40157', '40159', '40160', '40161', '40162', '40165', '40166', '40170', '40171', '40175', '40176', '40177', '40178', '40201', '40202', '40203', '40204', '40205', '40206', '40207', '40208', '40209', '40210', '40211', '40212', '40213', '40214', '40215', '40216', '40217', '40218', '40219', '40220', '40221', '40222', '40223', '40224', '40225', '40228', '40229', '40231', '40232', '40233', '40241', '40242', '40243', '40245', '40250', '40251', '40252', '40253', '40255', '40256', '40257', '40258', '40259', '40261', '40266', '40268', '40269', '40270', '40272', '40280', '40281', '40282', '40283', '40285', '40287', '40289', '40290', '40291', '40292', '40293', '40294', '40295', '40296', '40297', '40298', '40299', '40310', '40311', '40312', '40313', '40316', '40317', '40319', '40322', '40324', '40328', '40330', '40334', '40336', '40337', '40339', '40340', '40342', '40346', '40347', '40348', '40350', '40351', '40353', '40355', '40356', '40357', '40358', '40359', '40360', '40361', '40362', '40363', '40370', '40371', '40372', '40374', '40376', '40379', '40380', '40383', '40384', '40385', '40387', '40390', '40391', '40392', '40402', '40403', '40404', '40405', '40409', '40410', '40419', '40422', '40423', '40434', '40437', '40440', '40442', '40444', '40445', '40447', '40448', '40452', '40456', '40460', '40461', '40464', '40468', '40472', '40473', '40475', '40476', '40481', '40484', '40486', '40488', '40489', '40492', '40502', '40503', '40504', '40505', '40506', '40507', '40508', '40509', '40510', '40511', '40512', '40513', '40514', '40515', '40516', '40517', '40522', '40523', '40524', '40526', '40533', '40536', '40544', '40546', '40550', '40555', '40574', '40575', '40576', '40577', '40578', '40579', '40580', '40581', '40582', '40583', '40588', '40591', '40598', '40601', '40602', '40603', '40604', '40618', '40619', '40620', '40621', '40622', '40701', '40702', '40724', '40729', '40730', '40734', '40737', '40740', '40741', '40742', '40743', '40744', '40745', '40750', '40755', '40759', '40763', '40769', '40771', '40801', '40803', '40806', '40807', '40808', '40810', '40813', '40815', '40816', '40818', '40819', '40820', '40823', '40824', '40826', '40827', '40828', '40829', '40830', '40831', '40840', '40843', '40844', '40845', '40847', '40849', '40854', '40855', '40856', '40858', '40862', '40863', '40865', '40868', '40870', '40873', '40874', '40902', '40903', '40906', '40913', '40914', '40915', '40921', '40923', '40927', '40930', '40932', '40935', '40939', '40940', '40941', '40943', '40944', '40946', '40949', '40951', '40953', '40955', '40958', '40962', '40964', '40965', '40972', '40977', '40979', '40981', '40982', '40983', '40988', '40995', '40997', '41001', '41002', '41003', '41004', '41005', '41006', '41007', '41008', '41010', '41011', '41012', '41014', '41015', '41016', '41017', '41018', '41019', '41021', '41022', '41025', '41030', '41031', '41033', '41034', '41035', '41037', '41039', '41040', '41041', '41042', '41043', '41044', '41045', '41046', '41048', '41049', '41051', '41052', '41053', '41054', '41055', '41056', '41059', '41061', '41062', '41063', '41064', '41071', '41072', '41073', '41074', '41075', '41076', '41080', '41081', '41083', '41085', '41086', '41091', '41092', '41093', '41094', '41095', '41096', '41097', '41098', '41099', '41101', '41102', '41105', '41114', '41121', '41124', '41128', '41129', '41132', '41135', '41139', '41141', '41142', '41143', '41144', '41146', '41149', '41159', '41160', '41164', '41166', '41168', '41169', '41171', '41173', '41174', '41175', '41179', '41180', '41181', '41183', '41189', '41201', '41203', '41204', '41214', '41216', '41219', '41222', '41224', '41226', '41230', '41231', '41232', '41234', '41238', '41240', '41250', '41254', '41255', '41256', '41257', '41260', '41262', '41263', '41264', '41265', '41267', '41268', '41271', '41274', '41301', '41310', '41311', '41314', '41317', '41332', '41339', '41347', '41348', '41351', '41352', '41360', '41364', '41365', '41366', '41367', '41368', '41385', '41386', '41390', '41397', '41408', '41413', '41421', '41425', '41426', '41451', '41464', '41465', '41472', '41477', '41501', '41502', '41503', '41512', '41513', '41514', '41517', '41519', '41520', '41522', '41524', '41526', '41527', '41528', '41531', '41534', '41535', '41537', '41538', '41539', '41540', '41542', '41543', '41544', '41547', '41548', '41549', '41553', '41554', '41555', '41557', '41558', '41559', '41560', '41561', '41562', '41563', '41564', '41566', '41567', '41568', '41571', '41572', '41601', '41602', '41603', '41604', '41605', '41606', '41607', '41612', '41615', '41616', '41619', '41621', '41622', '41630', '41631', '41632', '41635', '41636', '41640', '41642', '41643', '41645', '41647', '41649', '41650', '41651', '41653', '41655', '41659', '41660', '41663', '41666', '41667', '41669', '41701', '41702', '41712', '41713', '41714', '41719', '41721', '41722', '41723', '41725', '41727', '41729', '41731', '41735', '41736', '41739', '41740', '41743', '41745', '41746', '41749', '41751', '41754', '41759', '41760', '41762', '41763', '41764', '41766', '41772', '41773', '41774', '41775', '41776', '41777', '41778', '41804', '41810', '41812', '41815', '41817', '41819', '41821', '41822', '41824', '41825', '41826', '41828', '41831', '41832', '41833', '41834', '41835', '41836', '41837', '41838', '41839', '41840', '41843', '41844', '41845', '41847', '41848', '41849', '41855', '41858', '41859', '41861', '41862', '42001', '42002', '42003', '42020', '42021', '42022', '42023', '42024', '42025', '42027', '42028', '42029', '42031', '42032', '42033', '42035', '42036', '42037', '42038', '42039', '42040', '42041', '42044', '42045', '42047', '42048', '42049', '42050', '42051', '42053', '42054', '42055', '42056', '42058', '42060', '42061', '42063', '42064', '42066', '42069', '42070', '42071', '42076', '42078', '42079', '42081', '42082', '42083', '42085', '42086', '42087', '42088', '42101', '42102', '42103', '42104', '42120', '42122', '42123', '42124', '42127', '42128', '42129', '42130', '42131', '42133', '42134', '42135', '42140', '42141', '42142', '42151', '42152', '42153', '42154', '42156', '42157', '42159', '42160', '42163', '42164', '42166', '42167', '42170', '42171', '42201', '42202', '42204', '42206', '42207', '42210', '42211', '42214', '42215', '42216', '42217', '42219', '42220', '42221', '42223', '42232', '42234', '42236', '42240', '42241', '42252', '42254', '42256', '42259', '42261', '42262', '42265', '42266', '42273', '42274', '42275', '42276', '42280', '42285', '42286', '42288', '42301', '42302', '42303', '42304', '42320', '42321', '42322', '42323', '42324', '42325', '42326', '42327', '42328', '42330', '42332', '42333', '42334', '42337', '42338', '42339', '42343', '42344', '42345', '42347', '42348', '42349', '42350', '42351', '42352', '42354', '42355', '42356', '42361', '42364', '42366', '42367', '42368', '42369', '42370', '42371', '42372', '42374', '42376', '42377', '42378', '42402', '42404', '42406', '42408', '42409', '42410', '42411', '42413', '42419', '42420', '42431', '42436', '42437', '42440', '42441', '42442', '42444', '42445', '42450', '42451', '42452', '42453', '42455', '42456', '42457', '42458', '42459', '42460', '42461', '42462', '42463', '42464', '42501', '42502', '42503', '42516', '42518', '42519', '42528', '42533', '42539', '42541', '42544', '42553', '42558', '42564', '42565', '42566', '42567', '42602', '42603', '42629', '42631', '42633', '42634', '42635', '42638', '42642', '42647', '42649', '42653', '42701', '42702', '42712', '42713', '42715', '42716', '42717', '42718', '42719', '42720', '42721', '42722', '42724', '42726', '42728', '42729', '42732', '42733', '42740', '42741', '42742', '42743', '42746', '42748', '42749', '42753', '42754', '42755', '42757', '42758', '42759', '42762', '42764', '42765', '42776', '42782', '42784', '42788']
df1 = pd.DataFrame(_zipcodeList)
df1.head()
| 0 | |
|---|---|
| 0 | 40003 |
| 1 | 40004 |
| 2 | 40006 |
| 3 | 40007 |
| 4 | 40008 |
Replace Header
df = df1.rename(columns={0:'Zip Code'})
df.head()
| Zip Code | |
|---|---|
| 0 | 40003 |
| 1 | 40004 |
| 2 | 40006 |
| 3 | 40007 |
| 4 | 40008 |
Find Duplicates
# finding duplicates in zipcodelist
df.drop_duplicates()
| Zip Code | |
|---|---|
| 0 | 40003 |
| 1 | 40004 |
| 2 | 40006 |
| 3 | 40007 |
| 4 | 40008 |
| ... | ... |
| 939 | 42765 |
| 940 | 42776 |
| 941 | 42782 |
| 942 | 42784 |
| 943 | 42788 |
944 rows × 1 columns
Find and drop outliers or missing data
df.dropna()
| Zip Code | |
|---|---|
| 0 | 40003 |
| 1 | 40004 |
| 2 | 40006 |
| 3 | 40007 |
| 4 | 40008 |
| ... | ... |
| 939 | 42765 |
| 940 | 42776 |
| 941 | 42782 |
| 942 | 42784 |
| 943 | 42788 |
944 rows × 1 columns
Fix casing or inconsistent values
# checking each value count and uniqueness of all variable
df['Zip Code'].value_counts()
df['Zip Code'].unique()
array(['40003', '40004', '40006', '40007', '40008', '40009', '40010',
'40011', '40012', '40013', '40014', '40018', '40019', '40020',
'40022', '40023', '40025', '40026', '40027', '40031', '40032',
'40033', '40036', '40037', '40040', '40041', '40045', '40046',
'40047', '40048', '40049', '40050', '40051', '40052', '40055',
'40056', '40057', '40058', '40059', '40060', '40061', '40062',
'40063', '40065', '40066', '40067', '40068', '40069', '40070',
'40071', '40075', '40076', '40077', '40078', '40104', '40107',
'40108', '40109', '40110', '40111', '40115', '40117', '40118',
'40119', '40121', '40122', '40129', '40140', '40142', '40143',
'40144', '40145', '40146', '40150', '40152', '40153', '40155',
'40157', '40159', '40160', '40161', '40162', '40165', '40166',
'40170', '40171', '40175', '40176', '40177', '40178', '40201',
'40202', '40203', '40204', '40205', '40206', '40207', '40208',
'40209', '40210', '40211', '40212', '40213', '40214', '40215',
'40216', '40217', '40218', '40219', '40220', '40221', '40222',
'40223', '40224', '40225', '40228', '40229', '40231', '40232',
'40233', '40241', '40242', '40243', '40245', '40250', '40251',
'40252', '40253', '40255', '40256', '40257', '40258', '40259',
'40261', '40266', '40268', '40269', '40270', '40272', '40280',
'40281', '40282', '40283', '40285', '40287', '40289', '40290',
'40291', '40292', '40293', '40294', '40295', '40296', '40297',
'40298', '40299', '40310', '40311', '40312', '40313', '40316',
'40317', '40319', '40322', '40324', '40328', '40330', '40334',
'40336', '40337', '40339', '40340', '40342', '40346', '40347',
'40348', '40350', '40351', '40353', '40355', '40356', '40357',
'40358', '40359', '40360', '40361', '40362', '40363', '40370',
'40371', '40372', '40374', '40376', '40379', '40380', '40383',
'40384', '40385', '40387', '40390', '40391', '40392', '40402',
'40403', '40404', '40405', '40409', '40410', '40419', '40422',
'40423', '40434', '40437', '40440', '40442', '40444', '40445',
'40447', '40448', '40452', '40456', '40460', '40461', '40464',
'40468', '40472', '40473', '40475', '40476', '40481', '40484',
'40486', '40488', '40489', '40492', '40502', '40503', '40504',
'40505', '40506', '40507', '40508', '40509', '40510', '40511',
'40512', '40513', '40514', '40515', '40516', '40517', '40522',
'40523', '40524', '40526', '40533', '40536', '40544', '40546',
'40550', '40555', '40574', '40575', '40576', '40577', '40578',
'40579', '40580', '40581', '40582', '40583', '40588', '40591',
'40598', '40601', '40602', '40603', '40604', '40618', '40619',
'40620', '40621', '40622', '40701', '40702', '40724', '40729',
'40730', '40734', '40737', '40740', '40741', '40742', '40743',
'40744', '40745', '40750', '40755', '40759', '40763', '40769',
'40771', '40801', '40803', '40806', '40807', '40808', '40810',
'40813', '40815', '40816', '40818', '40819', '40820', '40823',
'40824', '40826', '40827', '40828', '40829', '40830', '40831',
'40840', '40843', '40844', '40845', '40847', '40849', '40854',
'40855', '40856', '40858', '40862', '40863', '40865', '40868',
'40870', '40873', '40874', '40902', '40903', '40906', '40913',
'40914', '40915', '40921', '40923', '40927', '40930', '40932',
'40935', '40939', '40940', '40941', '40943', '40944', '40946',
'40949', '40951', '40953', '40955', '40958', '40962', '40964',
'40965', '40972', '40977', '40979', '40981', '40982', '40983',
'40988', '40995', '40997', '41001', '41002', '41003', '41004',
'41005', '41006', '41007', '41008', '41010', '41011', '41012',
'41014', '41015', '41016', '41017', '41018', '41019', '41021',
'41022', '41025', '41030', '41031', '41033', '41034', '41035',
'41037', '41039', '41040', '41041', '41042', '41043', '41044',
'41045', '41046', '41048', '41049', '41051', '41052', '41053',
'41054', '41055', '41056', '41059', '41061', '41062', '41063',
'41064', '41071', '41072', '41073', '41074', '41075', '41076',
'41080', '41081', '41083', '41085', '41086', '41091', '41092',
'41093', '41094', '41095', '41096', '41097', '41098', '41099',
'41101', '41102', '41105', '41114', '41121', '41124', '41128',
'41129', '41132', '41135', '41139', '41141', '41142', '41143',
'41144', '41146', '41149', '41159', '41160', '41164', '41166',
'41168', '41169', '41171', '41173', '41174', '41175', '41179',
'41180', '41181', '41183', '41189', '41201', '41203', '41204',
'41214', '41216', '41219', '41222', '41224', '41226', '41230',
'41231', '41232', '41234', '41238', '41240', '41250', '41254',
'41255', '41256', '41257', '41260', '41262', '41263', '41264',
'41265', '41267', '41268', '41271', '41274', '41301', '41310',
'41311', '41314', '41317', '41332', '41339', '41347', '41348',
'41351', '41352', '41360', '41364', '41365', '41366', '41367',
'41368', '41385', '41386', '41390', '41397', '41408', '41413',
'41421', '41425', '41426', '41451', '41464', '41465', '41472',
'41477', '41501', '41502', '41503', '41512', '41513', '41514',
'41517', '41519', '41520', '41522', '41524', '41526', '41527',
'41528', '41531', '41534', '41535', '41537', '41538', '41539',
'41540', '41542', '41543', '41544', '41547', '41548', '41549',
'41553', '41554', '41555', '41557', '41558', '41559', '41560',
'41561', '41562', '41563', '41564', '41566', '41567', '41568',
'41571', '41572', '41601', '41602', '41603', '41604', '41605',
'41606', '41607', '41612', '41615', '41616', '41619', '41621',
'41622', '41630', '41631', '41632', '41635', '41636', '41640',
'41642', '41643', '41645', '41647', '41649', '41650', '41651',
'41653', '41655', '41659', '41660', '41663', '41666', '41667',
'41669', '41701', '41702', '41712', '41713', '41714', '41719',
'41721', '41722', '41723', '41725', '41727', '41729', '41731',
'41735', '41736', '41739', '41740', '41743', '41745', '41746',
'41749', '41751', '41754', '41759', '41760', '41762', '41763',
'41764', '41766', '41772', '41773', '41774', '41775', '41776',
'41777', '41778', '41804', '41810', '41812', '41815', '41817',
'41819', '41821', '41822', '41824', '41825', '41826', '41828',
'41831', '41832', '41833', '41834', '41835', '41836', '41837',
'41838', '41839', '41840', '41843', '41844', '41845', '41847',
'41848', '41849', '41855', '41858', '41859', '41861', '41862',
'42001', '42002', '42003', '42020', '42021', '42022', '42023',
'42024', '42025', '42027', '42028', '42029', '42031', '42032',
'42033', '42035', '42036', '42037', '42038', '42039', '42040',
'42041', '42044', '42045', '42047', '42048', '42049', '42050',
'42051', '42053', '42054', '42055', '42056', '42058', '42060',
'42061', '42063', '42064', '42066', '42069', '42070', '42071',
'42076', '42078', '42079', '42081', '42082', '42083', '42085',
'42086', '42087', '42088', '42101', '42102', '42103', '42104',
'42120', '42122', '42123', '42124', '42127', '42128', '42129',
'42130', '42131', '42133', '42134', '42135', '42140', '42141',
'42142', '42151', '42152', '42153', '42154', '42156', '42157',
'42159', '42160', '42163', '42164', '42166', '42167', '42170',
'42171', '42201', '42202', '42204', '42206', '42207', '42210',
'42211', '42214', '42215', '42216', '42217', '42219', '42220',
'42221', '42223', '42232', '42234', '42236', '42240', '42241',
'42252', '42254', '42256', '42259', '42261', '42262', '42265',
'42266', '42273', '42274', '42275', '42276', '42280', '42285',
'42286', '42288', '42301', '42302', '42303', '42304', '42320',
'42321', '42322', '42323', '42324', '42325', '42326', '42327',
'42328', '42330', '42332', '42333', '42334', '42337', '42338',
'42339', '42343', '42344', '42345', '42347', '42348', '42349',
'42350', '42351', '42352', '42354', '42355', '42356', '42361',
'42364', '42366', '42367', '42368', '42369', '42370', '42371',
'42372', '42374', '42376', '42377', '42378', '42402', '42404',
'42406', '42408', '42409', '42410', '42411', '42413', '42419',
'42420', '42431', '42436', '42437', '42440', '42441', '42442',
'42444', '42445', '42450', '42451', '42452', '42453', '42455',
'42456', '42457', '42458', '42459', '42460', '42461', '42462',
'42463', '42464', '42501', '42502', '42503', '42516', '42518',
'42519', '42528', '42533', '42539', '42541', '42544', '42553',
'42558', '42564', '42565', '42566', '42567', '42602', '42603',
'42629', '42631', '42633', '42634', '42635', '42638', '42642',
'42647', '42649', '42653', '42701', '42702', '42712', '42713',
'42715', '42716', '42717', '42718', '42719', '42720', '42721',
'42722', '42724', '42726', '42728', '42729', '42732', '42733',
'42740', '42741', '42742', '42743', '42746', '42748', '42749',
'42753', '42754', '42755', '42757', '42758', '42759', '42762',
'42764', '42765', '42776', '42782', '42784', '42788'], dtype=object)
Seems like our scraped zip code data are all unique and no inconsistent zip code value presented.
One last look at our data frame before we move to the next step of the project next week~
df_zip_codes = df
df_zip_codes
| Zip Code | |
|---|---|
| 0 | 40003 |
| 1 | 40004 |
| 2 | 40006 |
| 3 | 40007 |
| 4 | 40008 |
| ... | ... |
| 939 | 42765 |
| 940 | 42776 |
| 941 | 42782 |
| 942 | 42784 |
| 943 | 42788 |
944 rows × 1 columns
Next step in the project, I will use all of these scraped Louisville_Zip_codes to pull weather information with my API datasource!
Milestone 4 (API data source)
Previously, Milestone 3 goal was to scrape all available Zip codes from Kentucky and put all of the Zip codes into a dataframe. This week’s milestone 4 will use that dataframe to pull weather information using API on OpenWeatherMap
# import libraries
import requests
from bs4 import BeautifulSoup
import requests
import json
import pandas as pd
import pprint
import datetime
import time
# define get_weather function to extract data from API
def get_weather(code):
API_KEY = 'enteryourAPIkeyhere'
url_base = 'http://api.openweathermap.org/data/2.5/weather?'
url = url_base+'zip='+code+',us&appid='+API_KEY+'&units=imperial'
r = requests.get(url)
data = r.json()
return data
# create used zip codes list and weather data list
used_list = []
weather_data = []
# extract data from API using each zip code from list
for zc in _zipcodeList[:len(_zipcodeList)]:
# if zip code is not in used list perform next steps and append the used zipcode list
if zc not in used_list :
used_list.append(zc)
# try to get weather data from API and append weather_data list
try:
data1 = get_weather(zc)
# wait for 0.2 sec to move to another step to limit number of calls per minute
time.sleep(0.2)
weather_data.append(data1)
# prints message to user if unable to open url
except requests.exceptions.ConnectionError as errc:
# handle ConnectionError exception
print('\033[91m ' +'***Connection Failure. Please try later.***'+'\033[0m')
break
# handle all other exceptions
except Exception as e:
print('\033[91m '+"Failure to Retrieve.Please try again"+'\033[0m')
len(weather_data)
944
len(used_list)
944
# using == to check if lists are equal
if used_list == _zipcodeList:
print ("The lists are identical")
else :
print ("The lists are not identical")
The lists are identical
# create 'weather.json' file with weather data
with open('weather.json', 'w') as outfile:
json.dump(weather_data, outfile)
1. Format data into a more readable format
import ujson
import pandas as pd
with open('weather.json') as f:
data = ujson.load(f)
df = pd.io.json.json_normalize(data)
df
| weather | base | dt | timezone | id | name | cod | coord.lon | coord.lat | main.temp | ... | clouds.all | sys.type | sys.id | sys.country | sys.sunrise | sys.sunset | visibility | wind.gust | message | rain.1h | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | [{'id': 804, 'main': 'Clouds', 'description': ... | stations | 1.590300e+09 | -14400.0 | 0.0 | Bagdad | 200 | -85.07 | 38.26 | 65.66 | ... | 98.0 | 3.0 | 2013083.0 | US | 1.590316e+09 | 1.590368e+09 | NaN | NaN | NaN | NaN |
| 1 | [{'id': 800, 'main': 'Clear', 'description': '... | stations | 1.590300e+09 | -14400.0 | 0.0 | Bardstown | 200 | -85.46 | 37.81 | 64.81 | ... | 1.0 | 1.0 | 3505.0 | US | 1.590316e+09 | 1.590368e+09 | 16093.0 | NaN | NaN | NaN |
| 2 | [{'id': 800, 'main': 'Clear', 'description': '... | stations | 1.590300e+09 | -14400.0 | 0.0 | Bedford | 200 | -85.31 | 38.59 | 65.14 | ... | 1.0 | 1.0 | 4519.0 | US | 1.590316e+09 | 1.590368e+09 | 16093.0 | NaN | NaN | NaN |
| 3 | [{'id': 804, 'main': 'Clouds', 'description': ... | stations | 1.590300e+09 | -14400.0 | 0.0 | Bethlehem | 200 | -85.02 | 38.45 | 66.00 | ... | 99.0 | 3.0 | 2033834.0 | US | 1.590316e+09 | 1.590368e+09 | NaN | 1.01 | NaN | NaN |
| 4 | [{'id': 800, 'main': 'Clear', 'description': '... | stations | 1.590300e+09 | -14400.0 | 0.0 | Bloomfield | 200 | -85.29 | 37.91 | 64.81 | ... | 1.0 | 1.0 | 3505.0 | US | 1.590316e+09 | 1.590368e+09 | 16093.0 | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 939 | [{'id': 800, 'main': 'Clear', 'description': '... | stations | 1.590300e+09 | -18000.0 | 0.0 | Munfordville | 200 | -85.92 | 37.29 | 70.00 | ... | 1.0 | 1.0 | 4225.0 | US | 1.590316e+09 | 1.590368e+09 | 16093.0 | NaN | NaN | NaN |
| 940 | [{'id': 800, 'main': 'Clear', 'description': '... | stations | 1.590300e+09 | -14400.0 | 0.0 | Sonora | 200 | -85.92 | 37.52 | 66.60 | ... | 1.0 | 1.0 | 3967.0 | US | 1.590316e+09 | 1.590368e+09 | 16093.0 | NaN | NaN | NaN |
| 941 | [{'id': 800, 'main': 'Clear', 'description': '... | stations | 1.590300e+09 | -18000.0 | 0.0 | Summersville | 200 | -85.62 | 37.34 | 69.22 | ... | 1.0 | 1.0 | 7308.0 | US | 1.590316e+09 | 1.590368e+09 | 16093.0 | NaN | NaN | NaN |
| 942 | [{'id': 800, 'main': 'Clear', 'description': '... | stations | 1.590300e+09 | -14400.0 | 0.0 | Upton | 200 | -85.91 | 37.46 | 68.18 | ... | 1.0 | 1.0 | 3967.0 | US | 1.590316e+09 | 1.590368e+09 | 16093.0 | NaN | NaN | NaN |
| 943 | [{'id': 800, 'main': 'Clear', 'description': '... | stations | 1.590300e+09 | -14400.0 | 0.0 | White Mills | 200 | -86.04 | 37.54 | 66.40 | ... | 1.0 | 1.0 | 3967.0 | US | 1.590316e+09 | 1.590368e+09 | 16093.0 | NaN | NaN | NaN |
944 rows × 27 columns
df_clean = pd.concat([df.drop(['weather'], axis=1),
df['weather'].apply(pd.Series)], axis=1)
df_clean
| base | dt | timezone | id | name | cod | coord.lon | coord.lat | main.temp | main.feels_like | ... | sys.type | sys.id | sys.country | sys.sunrise | sys.sunset | visibility | wind.gust | message | rain.1h | 0 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | stations | 1.590300e+09 | -14400.0 | 0.0 | Bagdad | 200 | -85.07 | 38.26 | 65.66 | 70.41 | ... | 3.0 | 2013083.0 | US | 1.590316e+09 | 1.590368e+09 | NaN | NaN | NaN | NaN | {'id': 804, 'main': 'Clouds', 'description': '... |
| 1 | stations | 1.590300e+09 | -14400.0 | 0.0 | Bardstown | 200 | -85.46 | 37.81 | 64.81 | 66.96 | ... | 1.0 | 3505.0 | US | 1.590316e+09 | 1.590368e+09 | 16093.0 | NaN | NaN | NaN | {'id': 800, 'main': 'Clear', 'description': 'c... |
| 2 | stations | 1.590300e+09 | -14400.0 | 0.0 | Bedford | 200 | -85.31 | 38.59 | 65.14 | 67.84 | ... | 1.0 | 4519.0 | US | 1.590316e+09 | 1.590368e+09 | 16093.0 | NaN | NaN | NaN | {'id': 800, 'main': 'Clear', 'description': 'c... |
| 3 | stations | 1.590300e+09 | -14400.0 | 0.0 | Bethlehem | 200 | -85.02 | 38.45 | 66.00 | 70.92 | ... | 3.0 | 2033834.0 | US | 1.590316e+09 | 1.590368e+09 | NaN | 1.01 | NaN | NaN | {'id': 804, 'main': 'Clouds', 'description': '... |
| 4 | stations | 1.590300e+09 | -14400.0 | 0.0 | Bloomfield | 200 | -85.29 | 37.91 | 64.81 | 66.45 | ... | 1.0 | 3505.0 | US | 1.590316e+09 | 1.590368e+09 | 16093.0 | NaN | NaN | NaN | {'id': 800, 'main': 'Clear', 'description': 'c... |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 939 | stations | 1.590300e+09 | -18000.0 | 0.0 | Munfordville | 200 | -85.92 | 37.29 | 70.00 | 69.51 | ... | 1.0 | 4225.0 | US | 1.590316e+09 | 1.590368e+09 | 16093.0 | NaN | NaN | NaN | {'id': 800, 'main': 'Clear', 'description': 'c... |
| 940 | stations | 1.590300e+09 | -14400.0 | 0.0 | Sonora | 200 | -85.92 | 37.52 | 66.60 | 70.70 | ... | 1.0 | 3967.0 | US | 1.590316e+09 | 1.590368e+09 | 16093.0 | NaN | NaN | NaN | {'id': 800, 'main': 'Clear', 'description': 'c... |
| 941 | stations | 1.590300e+09 | -18000.0 | 0.0 | Summersville | 200 | -85.62 | 37.34 | 69.22 | 71.44 | ... | 1.0 | 7308.0 | US | 1.590316e+09 | 1.590368e+09 | 16093.0 | NaN | NaN | NaN | {'id': 800, 'main': 'Clear', 'description': 'c... |
| 942 | stations | 1.590300e+09 | -14400.0 | 0.0 | Upton | 200 | -85.91 | 37.46 | 68.18 | 73.02 | ... | 1.0 | 3967.0 | US | 1.590316e+09 | 1.590368e+09 | 16093.0 | NaN | NaN | NaN | {'id': 800, 'main': 'Clear', 'description': 'c... |
| 943 | stations | 1.590300e+09 | -14400.0 | 0.0 | White Mills | 200 | -86.04 | 37.54 | 66.40 | 70.41 | ... | 1.0 | 3967.0 | US | 1.590316e+09 | 1.590368e+09 | 16093.0 | NaN | NaN | NaN | {'id': 800, 'main': 'Clear', 'description': 'c... |
944 rows × 27 columns
df_clean = df.drop(['dt', 'sys.type', 'visibility', 'base', 'timezone', 'id', 'cod', 'coord.lon', 'coord.lat', 'sys.country', 'sys.id', 'rain.1h', 'clouds.all',
'wind.gust', 'sys.sunrise', 'sys.sunset', 'message'], axis=1)
df_clean
| weather | name | main.temp | main.feels_like | main.temp_min | main.temp_max | main.pressure | main.humidity | wind.speed | wind.deg | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | [{'id': 804, 'main': 'Clouds', 'description': ... | Bagdad | 65.66 | 70.41 | 64.99 | 66.99 | 1019.0 | 98.0 | 1.01 | 67.0 |
| 1 | [{'id': 800, 'main': 'Clear', 'description': '... | Bardstown | 64.81 | 66.96 | 64.40 | 64.99 | 1016.0 | 93.0 | 3.89 | 200.0 |
| 2 | [{'id': 800, 'main': 'Clear', 'description': '... | Bedford | 65.14 | 67.84 | 64.40 | 66.00 | 1016.0 | 100.0 | 4.70 | 150.0 |
| 3 | [{'id': 804, 'main': 'Clouds', 'description': ... | Bethlehem | 66.00 | 70.92 | 64.99 | 66.99 | 1016.0 | 98.0 | 1.01 | 82.0 |
| 4 | [{'id': 800, 'main': 'Clear', 'description': '... | Bloomfield | 64.81 | 66.45 | 64.40 | 64.99 | 1016.0 | 93.0 | 4.81 | 202.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 939 | [{'id': 800, 'main': 'Clear', 'description': '... | Munfordville | 70.00 | 69.51 | 66.20 | 72.00 | 1016.0 | 64.0 | 4.92 | 204.0 |
| 940 | [{'id': 800, 'main': 'Clear', 'description': '... | Sonora | 66.60 | 70.70 | 66.20 | 66.99 | 1016.0 | 100.0 | 3.36 | 70.0 |
| 941 | [{'id': 800, 'main': 'Clear', 'description': '... | Summersville | 69.22 | 71.44 | 66.20 | 71.60 | 1018.0 | 83.0 | 4.56 | 193.0 |
| 942 | [{'id': 800, 'main': 'Clear', 'description': '... | Upton | 68.18 | 73.02 | 66.20 | 71.60 | 1016.0 | 100.0 | 3.36 | 70.0 |
| 943 | [{'id': 800, 'main': 'Clear', 'description': '... | White Mills | 66.40 | 70.41 | 66.00 | 66.99 | 1016.0 | 100.0 | 3.36 | 70.0 |
944 rows × 10 columns
df_clean['weather'].dropna(inplace= True)
# "weather" is a list containing
# one dictionary item. This is probably not the most efficient approach, but in
# order to do away with the list type, I create one big list of all the dictionary
# items, convert that to a pandas dataframe, and then contcatenate that, column-wise,
# to the clean dataset.
from collections import ChainMap
w = []
for L in df_clean['weather']:
data = dict(ChainMap(*L))
w.append(data)
df_w = pd.DataFrame(w)
df_weather_clean = pd.concat([df_clean, df_w], axis=1)
df_weather_clean.drop(['weather', 'icon'], axis=1, inplace=True)
df_weather_clean
| name | main.temp | main.feels_like | main.temp_min | main.temp_max | main.pressure | main.humidity | wind.speed | wind.deg | id | main | description | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Bagdad | 65.66 | 70.41 | 64.99 | 66.99 | 1019.0 | 98.0 | 1.01 | 67.0 | 804.0 | Clouds | overcast clouds |
| 1 | Bardstown | 64.81 | 66.96 | 64.40 | 64.99 | 1016.0 | 93.0 | 3.89 | 200.0 | 800.0 | Clear | clear sky |
| 2 | Bedford | 65.14 | 67.84 | 64.40 | 66.00 | 1016.0 | 100.0 | 4.70 | 150.0 | 800.0 | Clear | clear sky |
| 3 | Bethlehem | 66.00 | 70.92 | 64.99 | 66.99 | 1016.0 | 98.0 | 1.01 | 82.0 | 804.0 | Clouds | overcast clouds |
| 4 | Bloomfield | 64.81 | 66.45 | 64.40 | 64.99 | 1016.0 | 93.0 | 4.81 | 202.0 | 800.0 | Clear | clear sky |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 939 | Munfordville | 70.00 | 69.51 | 66.20 | 72.00 | 1016.0 | 64.0 | 4.92 | 204.0 | 800.0 | Clear | clear sky |
| 940 | Sonora | 66.60 | 70.70 | 66.20 | 66.99 | 1016.0 | 100.0 | 3.36 | 70.0 | NaN | NaN | NaN |
| 941 | Summersville | 69.22 | 71.44 | 66.20 | 71.60 | 1018.0 | 83.0 | 4.56 | 193.0 | NaN | NaN | NaN |
| 942 | Upton | 68.18 | 73.02 | 66.20 | 71.60 | 1016.0 | 100.0 | 3.36 | 70.0 | NaN | NaN | NaN |
| 943 | White Mills | 66.40 | 70.41 | 66.00 | 66.99 | 1016.0 | 100.0 | 3.36 | 70.0 | NaN | NaN | NaN |
944 rows × 12 columns
df_weather_clean = df_weather_clean.drop(['main.feels_like', 'id', 'wind.deg', 'main.pressure'], axis=1)
df_weather_clean
| name | main.temp | main.temp_min | main.temp_max | main.humidity | wind.speed | main | description | |
|---|---|---|---|---|---|---|---|---|
| 0 | Bagdad | 65.66 | 64.99 | 66.99 | 98.0 | 1.01 | Clouds | overcast clouds |
| 1 | Bardstown | 64.81 | 64.40 | 64.99 | 93.0 | 3.89 | Clear | clear sky |
| 2 | Bedford | 65.14 | 64.40 | 66.00 | 100.0 | 4.70 | Clear | clear sky |
| 3 | Bethlehem | 66.00 | 64.99 | 66.99 | 98.0 | 1.01 | Clouds | overcast clouds |
| 4 | Bloomfield | 64.81 | 64.40 | 64.99 | 93.0 | 4.81 | Clear | clear sky |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 939 | Munfordville | 70.00 | 66.20 | 72.00 | 64.0 | 4.92 | Clear | clear sky |
| 940 | Sonora | 66.60 | 66.20 | 66.99 | 100.0 | 3.36 | NaN | NaN |
| 941 | Summersville | 69.22 | 66.20 | 71.60 | 83.0 | 4.56 | NaN | NaN |
| 942 | Upton | 68.18 | 66.20 | 71.60 | 100.0 | 3.36 | NaN | NaN |
| 943 | White Mills | 66.40 | 66.00 | 66.99 | 100.0 | 3.36 | NaN | NaN |
944 rows × 8 columns
2. Identify outliers and bad data
df_weather = df_weather_clean.dropna()
df_weather
| name | main.temp | main.temp_min | main.temp_max | main.humidity | wind.speed | main | description | |
|---|---|---|---|---|---|---|---|---|
| 0 | Bagdad | 65.66 | 64.99 | 66.99 | 98.0 | 1.01 | Clouds | overcast clouds |
| 1 | Bardstown | 64.81 | 64.40 | 64.99 | 93.0 | 3.89 | Clear | clear sky |
| 2 | Bedford | 65.14 | 64.40 | 66.00 | 100.0 | 4.70 | Clear | clear sky |
| 3 | Bethlehem | 66.00 | 64.99 | 66.99 | 98.0 | 1.01 | Clouds | overcast clouds |
| 4 | Bloomfield | 64.81 | 64.40 | 64.99 | 93.0 | 4.81 | Clear | clear sky |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 935 | Mannsville | 67.51 | 66.00 | 69.80 | 83.0 | 4.36 | Clear | clear sky |
| 936 | Marrowbone | 71.74 | 71.60 | 72.00 | 64.0 | 3.74 | Clear | clear sky |
| 937 | Millwood | 68.50 | 66.20 | 71.60 | 100.0 | 3.36 | Clear | clear sky |
| 938 | Mount Sherman | 67.41 | 66.20 | 69.80 | 83.0 | 4.29 | Clear | clear sky |
| 939 | Munfordville | 70.00 | 66.20 | 72.00 | 64.0 | 4.92 | Clear | clear sky |
936 rows × 8 columns
3. Find Duplicates
df_weather = df_weather.drop_duplicates()
df_weather
| name | main.temp | main.temp_min | main.temp_max | main.humidity | wind.speed | main | description | |
|---|---|---|---|---|---|---|---|---|
| 0 | Bagdad | 65.66 | 64.99 | 66.99 | 98.0 | 1.01 | Clouds | overcast clouds |
| 1 | Bardstown | 64.81 | 64.40 | 64.99 | 93.0 | 3.89 | Clear | clear sky |
| 2 | Bedford | 65.14 | 64.40 | 66.00 | 100.0 | 4.70 | Clear | clear sky |
| 3 | Bethlehem | 66.00 | 64.99 | 66.99 | 98.0 | 1.01 | Clouds | overcast clouds |
| 4 | Bloomfield | 64.81 | 64.40 | 64.99 | 93.0 | 4.81 | Clear | clear sky |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 935 | Mannsville | 67.51 | 66.00 | 69.80 | 83.0 | 4.36 | Clear | clear sky |
| 936 | Marrowbone | 71.74 | 71.60 | 72.00 | 64.0 | 3.74 | Clear | clear sky |
| 937 | Millwood | 68.50 | 66.20 | 71.60 | 100.0 | 3.36 | Clear | clear sky |
| 938 | Mount Sherman | 67.41 | 66.20 | 69.80 | 83.0 | 4.29 | Clear | clear sky |
| 939 | Munfordville | 70.00 | 66.20 | 72.00 | 64.0 | 4.92 | Clear | clear sky |
849 rows × 8 columns
4. Replace Headers
df_weather.rename(columns = {'name':'City', 'main.temp':'Temperature', 'main.temp_min':'Min_Temperature', 'main.temp_max':'Max_Temperature',
'main.humidity':'Humidity', 'wind.speed':'Wind_Speed', 'main':'Sky', 'description':'Description'}, inplace = True)
df_weather
| City | Temperature | Min_Temperature | Max_Temperature | Humidity | Wind_Speed | Sky | Description | |
|---|---|---|---|---|---|---|---|---|
| 0 | Bagdad | 65.66 | 64.99 | 66.99 | 98.0 | 1.01 | Clouds | overcast clouds |
| 1 | Bardstown | 64.81 | 64.40 | 64.99 | 93.0 | 3.89 | Clear | clear sky |
| 2 | Bedford | 65.14 | 64.40 | 66.00 | 100.0 | 4.70 | Clear | clear sky |
| 3 | Bethlehem | 66.00 | 64.99 | 66.99 | 98.0 | 1.01 | Clouds | overcast clouds |
| 4 | Bloomfield | 64.81 | 64.40 | 64.99 | 93.0 | 4.81 | Clear | clear sky |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 935 | Mannsville | 67.51 | 66.00 | 69.80 | 83.0 | 4.36 | Clear | clear sky |
| 936 | Marrowbone | 71.74 | 71.60 | 72.00 | 64.0 | 3.74 | Clear | clear sky |
| 937 | Millwood | 68.50 | 66.20 | 71.60 | 100.0 | 3.36 | Clear | clear sky |
| 938 | Mount Sherman | 67.41 | 66.20 | 69.80 | 83.0 | 4.29 | Clear | clear sky |
| 939 | Munfordville | 70.00 | 66.20 | 72.00 | 64.0 | 4.92 | Clear | clear sky |
849 rows × 8 columns
5. Fix casing or inconsistent values
# Description column casing fix
df_weather['Description'].value_counts()
# make everything to have consistent casing.
df_weather['Description'] = df_weather['Description'].str.title()
df_weather['Description'].value_counts()
Clear Sky 476
Overcast Clouds 152
Scattered Clouds 136
Broken Clouds 35
Moderate Rain 17
Mist 15
Light Rain 11
Heavy Intensity Rain 5
Fog 2
Name: Description, dtype: int64
df_weather
| City | Temperature | Min_Temperature | Max_Temperature | Humidity | Wind_Speed | Sky | Description | |
|---|---|---|---|---|---|---|---|---|
| 0 | Bagdad | 65.66 | 64.99 | 66.99 | 98.0 | 1.01 | Clouds | Overcast Clouds |
| 1 | Bardstown | 64.81 | 64.40 | 64.99 | 93.0 | 3.89 | Clear | Clear Sky |
| 2 | Bedford | 65.14 | 64.40 | 66.00 | 100.0 | 4.70 | Clear | Clear Sky |
| 3 | Bethlehem | 66.00 | 64.99 | 66.99 | 98.0 | 1.01 | Clouds | Overcast Clouds |
| 4 | Bloomfield | 64.81 | 64.40 | 64.99 | 93.0 | 4.81 | Clear | Clear Sky |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 935 | Mannsville | 67.51 | 66.00 | 69.80 | 83.0 | 4.36 | Clear | Clear Sky |
| 936 | Marrowbone | 71.74 | 71.60 | 72.00 | 64.0 | 3.74 | Clear | Clear Sky |
| 937 | Millwood | 68.50 | 66.20 | 71.60 | 100.0 | 3.36 | Clear | Clear Sky |
| 938 | Mount Sherman | 67.41 | 66.20 | 69.80 | 83.0 | 4.29 | Clear | Clear Sky |
| 939 | Munfordville | 70.00 | 66.20 | 72.00 | 64.0 | 4.92 | Clear | Clear Sky |
849 rows × 8 columns
# City column casing fix
df_weather['City'].value_counts()
# make everything to have consistent casing
df_weather['City'] = df_weather['City'].str.title()
df_weather['City'].value_counts()
Louisville 25
Lexington 8
Covington 5
Bowling Green 4
London 4
..
Philpot 1
Cave City 1
Falmouth 1
Happy 1
West Point 1
Name: City, Length: 779, dtype: int64
# Sky column casing fix
df_weather['Sky'].value_counts()
# make everything to have consistent casing
df_weather['Sky'] = df_weather['Sky'].str.title()
df_weather['Sky'].value_counts()
Clear 476
Clouds 323
Rain 33
Mist 15
Fog 2
Name: Sky, dtype: int64
df_weather
| City | Temperature | Min_Temperature | Max_Temperature | Humidity | Wind_Speed | Sky | Description | |
|---|---|---|---|---|---|---|---|---|
| 0 | Bagdad | 65.66 | 64.99 | 66.99 | 98.0 | 1.01 | Clouds | Overcast Clouds |
| 1 | Bardstown | 64.81 | 64.40 | 64.99 | 93.0 | 3.89 | Clear | Clear Sky |
| 2 | Bedford | 65.14 | 64.40 | 66.00 | 100.0 | 4.70 | Clear | Clear Sky |
| 3 | Bethlehem | 66.00 | 64.99 | 66.99 | 98.0 | 1.01 | Clouds | Overcast Clouds |
| 4 | Bloomfield | 64.81 | 64.40 | 64.99 | 93.0 | 4.81 | Clear | Clear Sky |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 935 | Mannsville | 67.51 | 66.00 | 69.80 | 83.0 | 4.36 | Clear | Clear Sky |
| 936 | Marrowbone | 71.74 | 71.60 | 72.00 | 64.0 | 3.74 | Clear | Clear Sky |
| 937 | Millwood | 68.50 | 66.20 | 71.60 | 100.0 | 3.36 | Clear | Clear Sky |
| 938 | Mount Sherman | 67.41 | 66.20 | 69.80 | 83.0 | 4.29 | Clear | Clear Sky |
| 939 | Munfordville | 70.00 | 66.20 | 72.00 | 64.0 | 4.92 | Clear | Clear Sky |
849 rows × 8 columns
This is our finished and cleaned dataframe using Zip codes scraped from a website (Milestone 3) and used those Zip codes to pull weather information data and stored into a dataframe (Milestone 4)
I will load one more flat file to include all zip codes with its associated cities for merging with common key “Zip codes”
import pandas as pd
df_KY_zip = pd.read_csv('KY Zip code list.csv')
df_KY_zip
| Zip Code | City | Counties | |
|---|---|---|---|
| 0 | 40003 | Bagdad | Shelby |
| 1 | 40004 | Bardstown | Nelson |
| 2 | 40006 | Bedford | Trimble |
| 3 | 40007 | Bethlehem | Henry |
| 4 | 40008 | Bloomfield | Nelson |
| ... | ... | ... | ... |
| 939 | 42765 | Munfordville | Hart |
| 940 | 42776 | Sonora | Hardin |
| 941 | 42782 | Summersville | Green |
| 942 | 42784 | Upton | Hardin |
| 943 | 42788 | White Mills | NaN |
944 rows × 3 columns
df_KY_zip.dtypes
Zip Code int64
City object
Counties object
dtype: object
df_zip_codes.dtypes
Zip Code object
dtype: object
df_KY_Zip = df_KY_zip.astype(str)
df_KY_Zip.dtypes
Zip Code object
City object
Counties object
dtype: object
df_city_zip = pd.merge(df_KY_Zip, df_zip_codes, on ='Zip Code', how='inner')
I have merged City and its associated Zip Code
df_city_zip
| Zip Code | City | Counties | |
|---|---|---|---|
| 0 | 40003 | Bagdad | Shelby |
| 1 | 40004 | Bardstown | Nelson |
| 2 | 40006 | Bedford | Trimble |
| 3 | 40007 | Bethlehem | Henry |
| 4 | 40008 | Bloomfield | Nelson |
| ... | ... | ... | ... |
| 939 | 42765 | Munfordville | Hart |
| 940 | 42776 | Sonora | Hardin |
| 941 | 42782 | Summersville | Green |
| 942 | 42784 | Upton | Hardin |
| 943 | 42788 | White Mills | nan |
944 rows × 3 columns
Next is to merge Zip code, city and weather df
df_city_weather = pd.merge(df_city_zip, df_weather, on ='City', how='inner')
df_city_weather
| Zip Code | City | Counties | Temperature | Min_Temperature | Max_Temperature | Humidity | Wind_Speed | Sky | Description | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 40003 | Bagdad | Shelby | 65.66 | 64.99 | 66.99 | 98.0 | 1.01 | Clouds | Overcast Clouds |
| 1 | 40004 | Bardstown | Nelson | 64.81 | 64.40 | 64.99 | 93.0 | 3.89 | Clear | Clear Sky |
| 2 | 40006 | Bedford | Trimble | 65.14 | 64.40 | 66.00 | 100.0 | 4.70 | Clear | Clear Sky |
| 3 | 40007 | Bethlehem | Henry | 66.00 | 64.99 | 66.99 | 98.0 | 1.01 | Clouds | Overcast Clouds |
| 4 | 40008 | Bloomfield | Nelson | 64.81 | 64.40 | 64.99 | 93.0 | 4.81 | Clear | Clear Sky |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2935 | 42758 | Mannsville | Taylor | 67.51 | 66.00 | 69.80 | 83.0 | 4.36 | Clear | Clear Sky |
| 2936 | 42759 | Marrowbone | Cumberland | 71.74 | 71.60 | 72.00 | 64.0 | 3.74 | Clear | Clear Sky |
| 2937 | 42762 | Millwood | Grayson | 68.50 | 66.20 | 71.60 | 100.0 | 3.36 | Clear | Clear Sky |
| 2938 | 42764 | Mount Sherman | Larue | 67.41 | 66.20 | 69.80 | 83.0 | 4.29 | Clear | Clear Sky |
| 2939 | 42765 | Munfordville | Hart | 70.00 | 66.20 | 72.00 | 64.0 | 4.92 | Clear | Clear Sky |
2940 rows × 10 columns
Check to see if there’s any duplicates
df_city_weather = df_city_weather.drop_duplicates(subset='Zip Code', keep="first")
df_city_weather
| Zip Code | City | Counties | Temperature | Min_Temperature | Max_Temperature | Humidity | Wind_Speed | Sky | Description | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 40003 | Bagdad | Shelby | 65.66 | 64.99 | 66.99 | 98.0 | 1.01 | Clouds | Overcast Clouds |
| 1 | 40004 | Bardstown | Nelson | 64.81 | 64.40 | 64.99 | 93.0 | 3.89 | Clear | Clear Sky |
| 2 | 40006 | Bedford | Trimble | 65.14 | 64.40 | 66.00 | 100.0 | 4.70 | Clear | Clear Sky |
| 3 | 40007 | Bethlehem | Henry | 66.00 | 64.99 | 66.99 | 98.0 | 1.01 | Clouds | Overcast Clouds |
| 4 | 40008 | Bloomfield | Nelson | 64.81 | 64.40 | 64.99 | 93.0 | 4.81 | Clear | Clear Sky |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2935 | 42758 | Mannsville | Taylor | 67.51 | 66.00 | 69.80 | 83.0 | 4.36 | Clear | Clear Sky |
| 2936 | 42759 | Marrowbone | Cumberland | 71.74 | 71.60 | 72.00 | 64.0 | 3.74 | Clear | Clear Sky |
| 2937 | 42762 | Millwood | Grayson | 68.50 | 66.20 | 71.60 | 100.0 | 3.36 | Clear | Clear Sky |
| 2938 | 42764 | Mount Sherman | Larue | 67.41 | 66.20 | 69.80 | 83.0 | 4.29 | Clear | Clear Sky |
| 2939 | 42765 | Munfordville | Hart | 70.00 | 66.20 | 72.00 | 64.0 | 4.92 | Clear | Clear Sky |
940 rows × 10 columns
We will only focus on Louisville, KY
df_louisville_weather = df_city_weather[df_city_weather['City'] == 'Louisville']
df_louisville_weather
| Zip Code | City | Counties | Temperature | Min_Temperature | Max_Temperature | Humidity | Wind_Speed | Sky | Description | |
|---|---|---|---|---|---|---|---|---|---|---|
| 94 | 40201 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky |
| 119 | 40202 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky |
| 144 | 40203 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky |
| 169 | 40204 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky |
| 194 | 40205 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1619 | 40295 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky |
| 1644 | 40296 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky |
| 1669 | 40297 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky |
| 1694 | 40298 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky |
| 1719 | 40299 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky |
66 rows × 10 columns
Last step is to merge louisville weather dataframe with Louisville crime dataframe
df_louisville = pd.merge(df_louisville_weather, df_crime_clean, on ='Zip Code', how='inner')
df_louisville
| Zip Code | City_x | Counties | Temperature | Min_Temperature | Max_Temperature | Humidity | Wind_Speed | Sky | Description | ID | year | crime | City_y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 40201 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 1071446 | 2017.0 | other | louisville |
| 1 | 40202 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 830810 | 2014.0 | assault | louisville |
| 2 | 40202 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 830848 | 2014.0 | assault | louisville |
| 3 | 40202 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 831195 | 2014.0 | theft/larceny | louisville |
| 4 | 40202 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 831285 | 2013.0 | theft/larceny | louisville |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 183363 | 40299 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 468205 | 2009.0 | vandalism | louisville |
| 183364 | 40299 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 485090 | 2009.0 | other | louisville |
| 183365 | 40299 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 487789 | 2009.0 | vehicle break-in/theft | louisville |
| 183366 | 40299 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 487790 | 2009.0 | motor vehicle theft | louisville |
| 183367 | 40299 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 468270 | 2009.0 | theft/larceny | louisville |
183368 rows × 14 columns
df_louisville = df_louisville.drop_duplicates(subset='ID', keep="first")
df_louisville
| Zip Code | City_x | Counties | Temperature | Min_Temperature | Max_Temperature | Humidity | Wind_Speed | Sky | Description | ID | year | crime | City_y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 40201 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 1071446 | 2017.0 | other | louisville |
| 1 | 40202 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 830810 | 2014.0 | assault | louisville |
| 2 | 40202 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 830848 | 2014.0 | assault | louisville |
| 3 | 40202 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 831195 | 2014.0 | theft/larceny | louisville |
| 4 | 40202 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 831285 | 2013.0 | theft/larceny | louisville |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 183363 | 40299 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 468205 | 2009.0 | vandalism | louisville |
| 183364 | 40299 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 485090 | 2009.0 | other | louisville |
| 183365 | 40299 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 487789 | 2009.0 | vehicle break-in/theft | louisville |
| 183366 | 40299 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 487790 | 2009.0 | motor vehicle theft | louisville |
| 183367 | 40299 | Louisville | Jefferson | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 468270 | 2009.0 | theft/larceny | louisville |
183368 rows × 14 columns
df_louisville.drop(['City_y', 'Counties'], axis=1, inplace=True)
df_louisville.rename(columns={'City_x':'City', 'year':'Year', 'crime':'Crime', 'Zip Code': 'Zip_code'}, inplace = True)
df_louisville_crime = df_louisville
This is our final cleaned, merged dataframe from all data sources
df_louisville_crime
| Zip_code | City | Temperature | Min_Temperature | Max_Temperature | Humidity | Wind_Speed | Sky | Description | ID | Year | Crime | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 40201 | Louisville | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 1071446 | 2017.0 | other |
| 1 | 40202 | Louisville | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 830810 | 2014.0 | assault |
| 2 | 40202 | Louisville | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 830848 | 2014.0 | assault |
| 3 | 40202 | Louisville | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 831195 | 2014.0 | theft/larceny |
| 4 | 40202 | Louisville | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 831285 | 2013.0 | theft/larceny |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 183363 | 40299 | Louisville | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 468205 | 2009.0 | vandalism |
| 183364 | 40299 | Louisville | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 485090 | 2009.0 | other |
| 183365 | 40299 | Louisville | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 487789 | 2009.0 | vehicle break-in/theft |
| 183366 | 40299 | Louisville | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 487790 | 2009.0 | motor vehicle theft |
| 183367 | 40299 | Louisville | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 468270 | 2009.0 | theft/larceny |
183368 rows × 12 columns
Storing our master dataframe into a database
from sqlalchemy import create_engine
import sqlite3
import numpy as np
import plotnine as p9
engine = create_engine('sqlite:///louisville_crime_data.db')
df_louisville_crime.to_sql(
name='louisville_crime',
con=engine,
index=False,
if_exists='replace'
)
# reading datafrom the database
pd.read_sql("SELECT * FROM louisville_crime",engine).head()
| Zip_code | City | Temperature | Min_Temperature | Max_Temperature | Humidity | Wind_Speed | Sky | Description | ID | Year | Crime | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 40201 | Louisville | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 1071446 | 2017.0 | other |
| 1 | 40202 | Louisville | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 830810 | 2014.0 | assault |
| 2 | 40202 | Louisville | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 830848 | 2014.0 | assault |
| 3 | 40202 | Louisville | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 831195 | 2014.0 | theft/larceny |
| 4 | 40202 | Louisville | 66.42 | 64.0 | 68.0 | 88.0 | 5.82 | Clear | Clear Sky | 831285 | 2013.0 | theft/larceny |
Pulling data from database to do some visualizations
Louisville Crime Distribution Based on Types Graph
# Plotting Crime Count based on Crime types
Crime = pd.read_sql("SELECT Crime FROM louisville_crime",engine).astype(str)
(p9.ggplot(data=Crime,
mapping=p9.aes(x='factor(Crime)'))
+ p9.geom_bar()
+ p9.theme_bw()
+ p9.theme(axis_text_x = p9.element_text(angle=90))
+ p9.xlab("Crime") + p9.ggtitle("Crime Count By Categories")
)
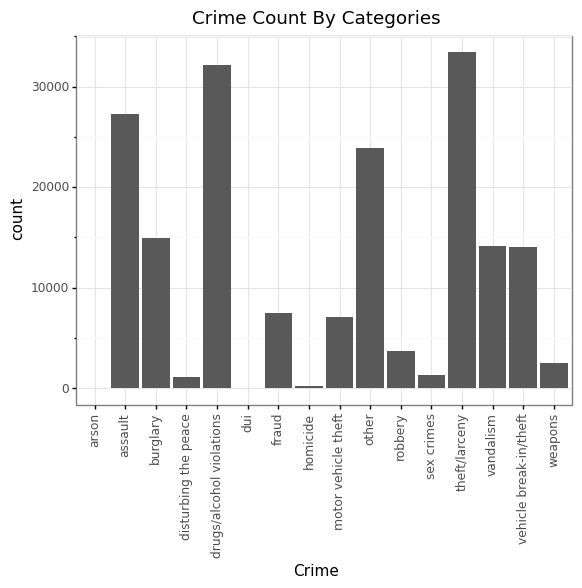
Based on the graph, we can see that theft/larceny and drugs/alcohol violations are among the top crimes in Louisville, KY
Crime Rate in Louisville throughout the years (2004 - 2017)
Year = pd.read_sql("SELECT Year FROM louisville_crime",engine).astype(float)
(p9.ggplot(data=Year,
mapping=p9.aes(x='factor(Year)'))
+ p9.geom_bar()
+ p9.theme_bw()
+ p9.theme(axis_text_x = p9.element_text(angle=90))
+ p9.ggtitle("Crime Rate Over The Years (2004-2017)")
+ p9.xlab("Year")
)
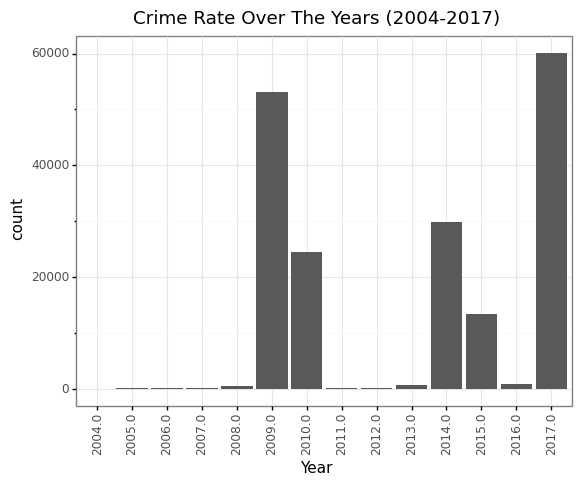
2017 had the highest crime count with 60,000 crimes in Louisville followed by 2009 with more than 50,000 crime count
2017 Crime Count based on Zip codes
zip_code = pd.read_sql("SELECT Zip_code FROM louisville_crime where Year = '2017'",engine).astype(str)
(p9.ggplot(data=zip_code,
mapping=p9.aes(x='Zip_code'))
+ p9.geom_bar()
+ p9.theme(axis_text_x = p9.element_text(angle=90))
+ p9.xlab("Zip code")
+ p9.ggtitle("Crime Distribution among all Louisville Zip codes in 2017")
)
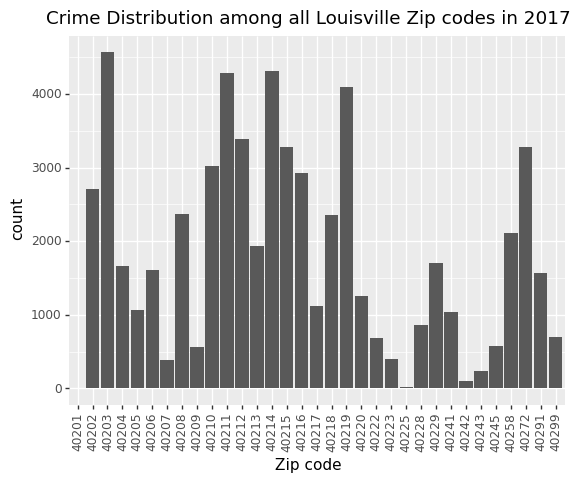
40203 is the Zip code in Louisville that has the highest Crime count in 2017, followed by 40211 and 40214
crime_40203 = pd.read_sql("SELECT Crime FROM louisville_crime where Zip_code = '40203' and Year = '2017'",engine).astype(str)
Looking at Crime Type distribution specifically for Zip code 40203 (Highest Crime Rate) for the Year 2017
(p9.ggplot(data=crime_40203,
mapping=p9.aes(x='factor(Crime)')) + p9.coord_flip()
+ p9.geom_bar()
+ p9.theme_bw()
+ p9.theme(axis_text_x = p9.element_text())
+ p9.labs(title = "Crime Rate Over The Years (2004-2017)", y = "Count", x = 'Crime Types'))
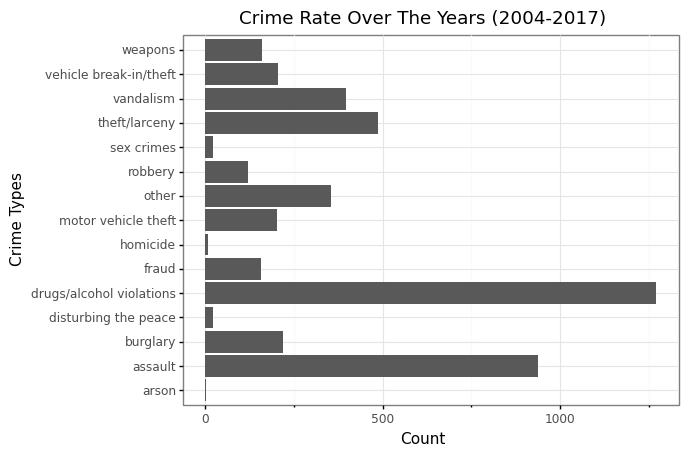
In 2017, Zip code 40203 had the highest crime count compared to all other Zip codes of Louisville. Drugs/alcohol violations contributed the most of these crimes
Variation of Temperatures between all 32 Zip codes of Louisville
temperatures = pd.read_sql("SELECT Temperature FROM louisville_crime group by Zip_code",engine).astype(float)
max_temp = pd.read_sql("SELECT Max_Temperature FROM louisville_crime group by Zip_code",engine).astype(float)
min_temp = pd.read_sql("SELECT Min_Temperature FROM louisville_crime group by Zip_code",engine).astype(float)
plt.plot(temperatures,label="Temperature")
plt.plot(max_temp,label="Max Temperature")
plt.plot(min_temp, label = "Min Temperature")
# Adding legend
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.title('Temperatures of all 32 Zip codes of Louisville')
plt.xlabel('Number of Louisville Zip codes')
plt.ylabel('Temperatures')
plt.show()

It looks like all Zip codes in Louisville had approximately the same temperatures
Wind and Humidity for all Zip codes in Louisville, KY
humid = pd.read_sql("SELECT Humidity FROM louisville_crime group by Zip_code" ,engine).astype(float)
wind = pd.read_sql("SELECT Wind_Speed FROM louisville_crime group by Zip_code",engine).astype(float)
plt.plot(humid, label = 'Humidity')
plt.plot(wind, label = 'Wind Speed')
# Adding legend, axis labels and Title
plt.title('Temperatures of all 32 Zip codes of Louisville')
plt.xlabel('Number of Louisville Zip codes')
plt.ylabel('Temperatures')
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.show()

For all 32 Zip codes of Louisville, it had similar humidity level of more than 80 and a wind speed of around 5-6
City of Louisville, KY Temperature Range
temperatures1 = pd.read_sql("SELECT Temperature, Max_Temperature, Min_Temperature FROM louisville_crime group by City",engine).astype(float)
plt.boxplot(temperatures1)
plt.title("Louisville Temperature Range")
plt.xlabel("Louisville Temperature")
plt.ylabel("Temperature")
plt.tick_params(
axis='x', # changes apply to the x-axis
which='both', # both major and minor ticks are affected
bottom=False, # ticks along the bottom edge are off
top=False, # ticks along the top edge are off
labelbottom=False) # labels along the bottom edge are off
plt.show()
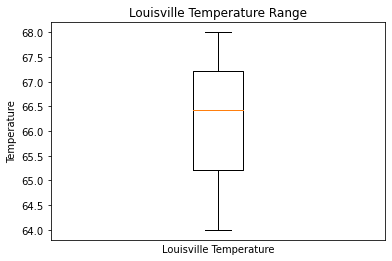
The temperature range of Louisville was at around 68 degree F with the minimum temperature around 66 F and maximum temperature appears to be around 70 F
Summary of what I learned and had to do to complete the project
Upon completion of this final project, this course has taught me so much. Before I began this project, I had no idea how to web scraping, somewhat knowledge of pulling API data and how to efficiently clean and perform data wrangling. I had to go through many tutorials, reading the books, and use other resources in order for me to complete this project and perform tasks that I needed to do like how to web scrape, store data into a database and when to appropriately use certain packages. In order for me to fully complete the project, I had to perform data wrangling on my flat files, API and website sources. Then merge all of them together using a common column variable and stored these into a database. After storing the cleaned final dataframe into a database, I can then pull the dataframe back out to do visualizations. For me, web scraping with BeautifulSoup was not as easy as I initially thought it to be. Furthermore, the part that I had to most difficult time was trying to store my pandas dataframes into a database. Pulling API data was also very challenging when it comes to cleaning and storing them into a data frame because the data that got pulled was not too clean and so I had to do a lot of manipulation and data wrangling in order for me to efficiently merged all of my data sources together.